Démêler les concepts d'explicabilité et de généralisation

1. Introduction
Les concepts en science des données peuvent très rapidement se ressembler quand on n’est pas directement impliqué du côté technique du domaine. Ainsi, des concepts comme la capacité de généralisation d’un modèle et l’explicabilité des modèles peuvent rapidement être confondus. Le but de cet article est de donner aux non-initiés un survol de ces concepts et d’énumérer quelques stratégies qui permettent de valider la généralisation d’un modèle peu importe si celui-ci est explicable ou non. Il est à noter que selon le contexte (contexte d’affaire, contexte réglementaire, contexte éthique), il peut être préférable d’utiliser des modèles qui permettent de comprendre le processus algorithmique et les choix faits par celui-ci alors que dans d’autres cas, seule la meilleure prédiction (sur de nouvelles données) nous importe. Il est important de comprendre qu’un modèle explicable n’est pas nécessairement généralisable et que dans certains cas, un modèle « boîte-noire » peut être davantage généralisable qu’un modèle explicable. Une approche possible reste toujours de tester des modèles explicables et des modèles « boîte-noire », d’évaluer leur généralisabilité et de choisir la solution finale déployée en fonction de la différence de performance entre les deux approches.
2. Modèles “boîte-noire” vs Modèles explicables

Avant d’entrer dans la définition d’un modèle dit « boîte-noire » et d’un modèle explicable, il est d’abord important de comprendre la différence entre l’interprétabilité et l’explicabilité d’un modèle. Gilpin et coll. [1] définissent l’interprétabilité d’un modèle comme étant la compréhension de ce qu’un modèle fait. Par exemple, si on prend le cas d’un réseau de neurones profond qui classifie des images, nous pouvons visualiser les endroits dans l’image où le modèle a défini et trouvé des patterns afin de faire sa classification sans toutefois comprendre précisément pourquoi l’image a été labellisée ainsi. Comme on peut le voir dans la figure de droite, le modèle construit des patterns associés à des visages de façon plus ou moins abstraite en fonction de la position dans le réseau profond (Les niveaux de gris au niveau 1 permettent de définir des frontières rectilignes au niveau 2 qui permettent de définir des éléments de visage comme un nez, une bouche au niveau 3, etc.). Ainsi, si on peut interpréter à un certain niveau le fonctionnement d’un tel modèle, il est cependant difficile, voire impossible, d’expliquer dans le détail ce que fait l’algorithme pour arriver à sa conclusion.
Un modèle explicable est quant à lui un modèle pour lequel il est possible d’expliquer ce qui se passe à l’intérieur de l’algorithme et de le mettre dans des termes qui sont compréhensibles par un humain. Ainsi, un modèle explicable est interprétable, mais l’inverse n’est pas nécessairement vrai. Dans cette optique, un modèle « boîte-noire » est un modèle pour lequel on peut en général interpréter le résultat, mais pas l’expliquer complètement en raison du nombre important de variables présentes dans le modèle ou de sa complexité. Ainsi, certains auteurs comme Rudin [2] proposent d’utiliser uniquement des modèles explicables pour motiver des décisions ayant un impact important pour une entreprise ou la société.
3. Décomposition de l’interprétabilité
Dans son livre Interpretable Machine Learning, contrairement à [1], Molnar [3] ne fait pas de distinction entre l’interprétabilité et l’explicabilité et utilise ces termes de façon interchangeable. Par contre, Mortar subdivise le concept d’interprétabilité en 5 catégories. Les questions auxquelles il tente de répondre ainsi que les concepts sont les suivants:
Transparence de l’algorithme: Comment l'algorithme crée-t-il le modèle ?
Interprétabilité globale du modèle: Comment le modèle entraîné fait-il des prédictions ?
Interprétabilité globale du modèle à un niveau modulaire: Comment les parties du modèle affectent-elles les prédictions ?
Interprétabilité locale pour une prédiction: Pourquoi le modèle a-t-il fait une certaine prédiction pour une observation donnée ?
Interprétabilité locale pour un groupe de prédictions: Pourquoi le modèle a-t-il fait des prédictions spécifiques pour un groupe d'observations ?
Finalement, le concept de XAI (“eXplainable Artificial Intelligence”) a été développé. Il regroupe les aspects de transparence, d’interprétabilité et d'applicabilité [5]. Nous constatons donc que différentes méthodes existent afin d’en évaluer l’interprétabilité et nous laissons la curiosité du lecteur l’inciter à aller fouiller afin d’en apprendre davantage.
4. Le lien entre l’explicabilité et la performance d’un modèle
Alors qu’il est parfois nécessaire de pouvoir expliquer comment et pourquoi le modèle fait ses prédictions, il est toujours souhaitable d’avoir un niveau de performance acceptable. Certains auteurs ont schématisé (cf. fig *ci-dessous*) la relation qui existe entre l’interprétatibilité d’une famille d’algorithmes et la précision des modèles qui sont générés. Ainsi, il faut donc évaluer les caractéristiques et besoins de son propre projet afin de faire le choix adéquat.
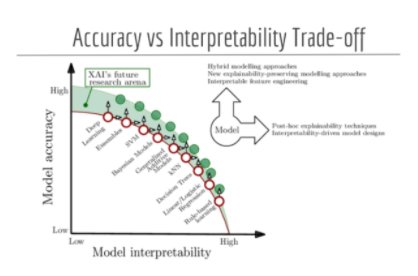
Source: DPhi Advanced ML Bootcamp — Explainable AI - DPhi Tech, Explainable AI Course, https://dphi.tech/lms/learn/explainable-ai/563
Il faut noter que la figure précédente est très générale et que selon le contexte, un modèle qui se situe plus bas sur l’axe de la précision peut être du même niveau de performance, voire plus performant que les modèles situés plus à l'extrême nord de l’axe. Afin de les comparer, une bonne pratique est d’avoir un modèle dit « baseline », qui est souvent moins complexe.
Indépendamment des concepts d’interprétabilité, d’explicabilité et de précision, il est capital de développer des modèles généralisables, afin de pouvoir être efficace sur de nouvelles observations que l’algorithme n’aura jamais vu. Le concept de généralisation s’applique à ces différents types de modèles.
5. Généralisation des modèles
L’importance d’avoir un modèle généralisable est dû au fait que l’on souhaite que le modèle performe bien sur des observations qu’il n’a jamais vues auparavant. Pour ce faire, différentes stratégies ou techniques existent dans le but de ne pas faire de sur ou sous-apprentissage. Si ces concepts vous sont inconnus, l’image ci-dessous est une bonne représentation. On souhaite que le modèle s’adapte bien à nos données, c’est-à-dire qu’il capture le mieux possible le « signal » qu’elles contiennent sans toutefois s’ajuster au bruit (car cette partie n’est pas généralisable). Dans ce dernier cas, cela veut dire que le modèle aurait appris un « pattern » qui n’est applicable qu’aux données qu’on lui a fournies durant l’entraînement.

Pour ce faire, on peut utiliser l’erreur de généralisation qui est l’erreur obtenue sur l’échantillon de test différent de celui d’entraînement, tel que l’on peut le constater sur le graphique suivant. Cette erreur de généralisation diminue avec la capacité du modèle (on est alors dans la phase de sous-apprentissage) jusqu’à un optimum, puis augmente lorsque la capacité du modèle continue de croître (on tombe alors en situation de surapprentissage). Mais qu’est-ce que la capacité d’un modèle? On peut définir la capacité d’un modèle par sa complexité ou par son aptitude à s’adapter à une grande variété de fonctions [3]. Un modèle linéaire aura donc une capacité moindre qu’un modèle quadratique par exemple. Ainsi, l’analyste doit trouver un « sweet spot » dans le but de limiter le sous ou sur-apprentissage du modèle. Voir l’image ci-dessous [4].

Différentes méthodes existent dans le but de sélectionner la bonne capacité de modèle et ainsi de réduire l’erreur de généralisation. Certaines sont présentées ci-dessous.
A) Indicateurs basés sur la vraisemblance
Dans le but de choisir un modèle probabiliste qui reproduit la distribution des données, certains indicateurs comme le AIC (Akaike Information Criterion) et le BIC (Bayesian Information Criterion) peuvent être utilisés afin d’éviter le sur-ajustement des données. Effectivement, ces indicateurs viennent pénaliser l’ajout de paramètres supplémentaires dans le modèle. Ils permettent ainsi de faire un compromis entre l’ajustement et la complexité du modèle. Cependant, ces métriques ne permettent pas de savoir directement si le modèle généralise bien les données. Effectivement, une fois plusieurs modèles ajustés, il est possible d’évaluer quel est le modèle qui permet d’avoir le meilleur compromis entre la qualité de l’ajustement et la complexité afin d’éviter le sur-ajustement. Néanmoins, on a aucune idée de la performance du modèle. On pourrait comparer ces métriques à une boussole: cela permet de savoir vers où se diriger, mais sans jamais avoir une idée de la distance parcourue ou ce qu’il reste à parcourir avant d’arriver à destination.
B) Méthodes basées sur la séparation de l’échantillon
Une des techniques communes qui permet 1) de maximiser la capacité de généralisation des modèles et 2) d’avoir une évaluation de cette capacité, est la division de l’échantillon. L'échantillonnage des données est ainsi l’une des parties primordiales lors du développement d’un modèle prédictif. Essentiellement, il est important d’analyser les données et de choisir la méthode d'échantillonnage appropriée tout en tenant compte de certaines contraintes comme la taille de l’échantillon ou le balancement des données, par exemple.
i) Échantillon d’entraînement, de validation et de test.
Lorsque le jeu de données est volumineux, avant de débuter l’entraînement d’un algorithme/modèle, on peut diviser son jeu de données en plusieurs échantillons. Pourquoi? Afin d’avoir des données qui n’auront jamais été vues par le modèle pour pouvoir estimer correctement la capacité de généralisation du modèle. Ainsi, on génère habituellement trois jeux de données. Un échantillon d’entraînement sur lequel on entraîne l’algorithme. Un échantillon de validation distinct de l’échantillon d’entraînement sur lequel on compare la performance de plusieurs modèles. Effectivement, il n’est pas rare que l’on entraîne plusieurs modèles différents qui tiennent compte de différents facteurs externes (variables) afin de trouver le meilleur modèle. Une fois que le meilleur modèle est défini, on sélectionne celui qui a l’erreur la plus faible sur l’échantillon de validation et on réévalue sa performance sur l’échantillon de test.
ii) Validation croisée

Lorsque l’on est en présence de petits échantillons, la division de l’échantillon en échantillons d’entraînement, de validation et de test peut être un problème. Dans un tel cas, on peut utiliser la technique de la validation croisée. Tel que démontré par la figure ci-haut, il s'agit d’une méthode qui consiste à diviser notre échantillon d'entraînement de façon à avoir un nombre k d’échantillons différents (souvent 5 ou 10) dans le but d’utiliser des données différentes lors de l’entraînement et la validation du modèle. Ainsi, si on reprend l’exemple de la figure, pour une validation croisée à 5 blocs, le modèle sera entraîné 5 fois. À chaque itération, les données qui serviront à ajuster le modèle seront différentes (les données en rose) et sa performance est analysée sur le reste des données (en bleu). En obtenant une ou des métriques de performances pour chacun des k entraînements et validations, on peut observer si notre modèle sur-apprend ou généralise bien nos données en faisant l’économie d’un échantillon de validation. Lorsque les paramètres du meilleur modèle ont été identifiés, on peut réentraîner notre modèle sur l’entièreté des données d'entraînement.
Enfin, d’autres techniques d’échantillonnage existent et peuvent être mieux adaptées au jeu de données que l’on utilise lors de la modélisation. Effectivement, selon le balancement du jeu de données, il est possible d’utiliser des techniques de suréchantillonnage (Random Oversampling, SMOTE, ADASYN, Data augmentation) ou de sous-échantillonnage (Random Undersampling, Tomek Links, Near-Miss).
C) Régularisation
La régularisation est une technique complémentaire aux deux techniques précédentes qui ont pour but de trouver le modèle dont la capacité est la plus adaptée à la complexité du problème à modéliser. Son principe est d’utiliser schématiquement un modèle trop complexe et qui devrait normalement conduire à du sur-apprentissage, mais d’utiliser des artifices pour ajuster la capacité effective de ces modèles.
i) Pénalisation des coefficients
Les deux méthodes les plus populaires pour la régularisation d’un modèle sont la régularisation avec les normes L1 et L2. Sans entrer dans la théorie et la complexité de ces méthodes, elles permettent de venir pénaliser les coefficients du modèle en les diminuant dans le but de se rapprocher ou de devenir zéro. Ainsi, pour prendre l’exemple de la figure X ci-dessus, on pourrait utiliser un modèle polynomial de degré 3, 4 ou 5 par exemple, mais à limiter les coefficients du modèle à de petites valeurs. Pour ce faire, un terme piloté par un paramètre (alpha) est ajouté à la fonction de perte (la fonction qu’on décide de minimiser afin de réduire l’erreur du modèle). Celui-ci peut être ajusté (c’est à dire que l’on ajuste la quantité de régularisation) dans le but d’atteindre de meilleures performances tout en diminuant les chances du modèle de faire du sur-apprentissage ou du sous-apprentissage. C’est une question de trouver le bon équilibre en ajustant cette valeur (cela peut être fait en validation croisée!). Ces méthodes peuvent être appliquées sur des modèles plus simples comme une régression linéaire tout comme sur des réseaux de neurones qui sont complexes.
D’autres méthodes de régularisation sont propres à certaines familles de modèles en particulier comme le « dropout » l’est pour les réseaux de neurones. Elles sont propres à certaines familles de modèle. Cette technique permet de réduire la complexité du réseau et de permettre au modèle d’être plus généralisable en réduisant le sur-entraînement.
6. Conclusion
Enfin, malgré que ces notions puissent sembler ardues, il est important de se rappeler qu’il faut limiter l’utilisation de certains modèles prédictifs aux besoins que l’on cherche à combler. Le premier critère à considérer est de savoir s'il est nécessaire de pouvoir interpréter et comprendre les prédictions du modèle entraîné. Si c’est le cas, on doit se limiter à certaines familles de modèles dites explicables. Somme toute, il faut tout de même que le modèle choisi reste généralisable à nos données et que ses performances soient répétées sur des données inconnues. Pour ce faire, certaines techniques peuvent être utilisées dans la quête de la généralisation.
[1] Gilpin, L. H., Bau, D., Yuan, B. Z., Bajwa, A., Specter, M., & Kagal, L. (2018, October). Explaining explanations: An overview of interpretability of machine learning. In 2018 IEEE 5th International Conference on data science and advanced analytics (DSAA) (pp. 80-89). IEEE.
[2] Rudin, C. (2019). Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature Machine Intelligence, 1(5), 206-215.
[3] Molnar, C. (2020). Interpretable machine learning. Lulu. com.
[4] Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT press. p.115
[5] Wikipedia, https://en.wikipedia.org/wiki/Explainable_artificial_intelligence, accédé le 21 septembre 2021.