Représentation de données en assurance avec réseaux Bayésiens

Comprendre son jeu de données peut souvent être une tâche complexe. Les modèles probabilistes graphiques (PGM) tels que les réseaux Bayésiens, permettent d’ajouter un niveau de compréhension du domaine d’étude en représentant graphiquement la structure des variables.
Les PGM utilisent des graphes pour représenter un espace de plusieurs dimensions et permettent d’encoder des relations entre les variables avec l’aide de modèles probabilistes.
Pour illustrer son utilisation, nous allons parcourir un jeu de données portant sur des informations de clients d’assurance automobile (20 000 observations, 27 variables). Voici un aperçu d’une partie des variables (toutes catégories) :

Un exemple de structure de réseau bayésien pour cet exemple:
![[image librairie R : bnlearn]](https://images.squarespace-cdn.com/content/v1/5e43403ddc6e0e7024d100ff/1614353988571-RD7WQUPE7Q6PTLSPZ7PC/B8hrbCzc2J2sswaAtp9xIA7ciEwAkRSMfCCfSYE82auUiiUFXYYbTIJgeGVyq66MFnNG6w0hJmDVGIg1SA-gY4T9LAC3g7KgOa6H2pQaWuUCNPafRmX66TnthNulxjs1s1KBJJ1c.png)
[image librairie R : bnlearn]
La tâche d'apprentissage d'un réseau Bayésien regroupe trois sous-tâches:
L'apprentissage structurel, c'est-à-dire l'identification de la topologie du réseau;
L'apprentissage paramétrique, c'est-à-dire l'estimation des paramètres numériques (les distributions de probabilités conditionnelles - CDP) pour un réseau donné.
Des requêtes d’inférence peuvent ainsi être faites à l’aide du graphe obtenu, en prenant par exemple une partie des variables d’une personne dans le but d’évaluer les distributions de d’autres variables d'intérêt.

Le but de l'article est de présenter certaines méthodes des deux premières étapes pour le jeu de données d’assurance automobile. Pour une meilleure compréhension, définissons quelques concepts.
Quelques concepts
Commençons par décrire quelques concepts appliqués à notre contexte.
Variables aléatoires : Les variables explicatives.
Probabilité conditionnelle : Prenons l’exemple de données d’assurance automobile. La probabilité qu’une personne ait un accident sachant qu’elle a déjà eu un accident s’exprime comme suit :
Probabilité ( Accident | déja eu des accidents)
Indépendance et dépendance : Lorsque l'événement d’avoir un accident n’est pas influencé par le fait d’avoir eu un accident par le passé, on dira que ces deux variables sont indépendantes, et dépendantes sinon.
L’ensemble des variables X1,X2..Xn est considéré comme indépendant si

Distribution de probabilité conditionnelle : Lorsque les variables sont catégorielles, une table de probabilité conditionnelle (CDP) est utilisée pour représenter les probabilités conditionnelles.

La distribution de probabilité conditionnelle de “Accident” étant donné “previous_accident” est la distribution de probabilité d'accident lorsque la valeur de “previous_accident” est connue.
Graphe : Dans la plupart des représentations graphiques, les nœuds correspondent aux variables aléatoires, et les arcs correspondent aux interactions probabilistes entre elles. [4]
Le graphique a pour but de capturer la manière dont les distributions conjointes sur toutes les variables doivent être décomposées, en un produit de facteurs chacun dépendant uniquement d’un sous-ensemble des variables.
Un exemple de graphe Bayésien simple (aussi appelé graphe orienté) :
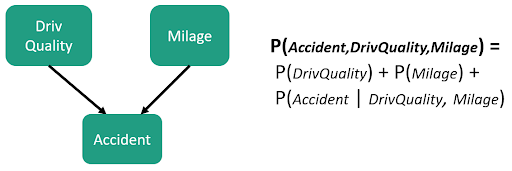
Réseau Bayésien : Les réseaux Bayésiens sont des graphes où les nœuds représentent des variables du domaine, et les arcs représentent des relations causales entre les variables [5]. On obtient donc une représentation compacte des distributions de probabilités conditionnelles (CDP).

DAG (Graphe Orientés Acycliques) : Dans cet article nous allons nous concentrer seulement sur les modèles graphiques dirigés, soit les modèles Bayésiens. Ces modèles ont la particularité d’être représentés par des graphes orientés acycliques (DAG), où l'on peut interpréter de manière informelle que l’arc X1→ X2 indique que X1 cause X2.
2. Étape 1 : Apprentissage de structure du réseau
La tâche est de trouver le graphe le plus représentatif des données. Les méthodes pour résoudre ce problème s’inspirent des méthodes d’optimisation. Il existe différentes approches d'apprentissage de structure de réseaux :
Les méthodes basées sur les scores (Likelihood, BIC, BDeu)
Les méthodes basées sur les contraintes
Les méthodes hybrides qui combinent les deux types d’approches
2.1 Méthodes basées sur les scores
Afin d’évaluer la vraisemblance du graphe par rapport aux données, les méthodes utilisent un score. Les différences de méthodes résident dans le type de score et le type d’étapes pour optimiser ce score. Cela peut se résumer à deux étapes :
Une fonction de score, qui détermine la vraisemblance entre les données et le graphe;
Un problème d’optimisation, pour maximiser ce même score.
Recherche par la méthode Hill-climbing
C’est une méthode d'optimisation permettant de trouver un optimum local parmi un ensemble de configurations. L’algorithme part d’un DAG non connecté, et manipule des arcs jusqu’à un minimum local. Cette méthode est similaire à la méthode de la descente de gradient, mais adaptée aux données discrètes, là où le gradient ne peut pas être défini.

En gardant 4 variables du jeu de données initial, nous obtenons le graphique suivant :

2.2 Méthode par contraintes
Cette approche repose sur la création d’une liste de contraintes, qui représente les liens entre les variables qu’il faut inclure dans le graphe final. Cela est fait dans un premier temps en identifiant les indépendances dans l'ensemble de données à l'aide de tests d'hypothèses. Ensuite on vient construire un DAG selon ses indépendances.
Le niveau de confiance pour les tests d’indépendance doit être fourni à la fonction.
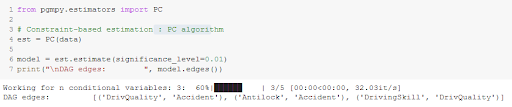
On obtient le même graphe que la méthode précédente :

Si le graphe est peu connecté (sparse) (i.e. peu de nœuds sont adjacents à beaucoup d’autres nœuds), l'algorithme PC est efficace [7].
2.3 Méthode hybride
Il existe aussi des méthodes hybrides qui combinent les deux types d’approches, en commençant par l’apprentissage d’un graphe non orienté avec les méthode basées sur les contraintes, et par l’orientation des liens avec une méthode de score.
La méthode MmhcEstimator.estimate() du package Python pgmpy effectue les deux étapes et estime directement un modèle Bayésien, mais la méthode n’est pas encore stable pour l’instant. D'autres bibliothèques sont plus complètes sur R, avec notamment Bnlearn.
Les méthodes du package pgmpy retournent une liste d’arcs sans visualisation du graphe, mais cela peut être fait avec quelques efforts de visualisation à l’aide de NetworkX par exemple.
3. Étape 2 : Apprentissage des paramètres
La tâche est d’estimer les valeurs des distributions de probabilités conditionnelles (CPD). Il existe plusieurs méthodes pour les estimer dont :
Maximum de vraisemblance (Maximum Likelihood Estimation)
Estimation Bayésienne (Bayesian Estimation)
Maximum de vraisemblance (Maximum Likelihood Estimation)
À partir du graphe construit lors de l’étape précédente et à partir des données, nous pouvons apprendre les probabilités conjointes à chacun des nœuds, en fonction de ses nœuds parents.

Commençons par créer un modèle Bayésien, qui contient des méthodes pour l'apprentissage des paramètres.

Un moyen d'exprimer les distributions de probabilités conjointe (CPD) est d'utiliser les fréquences relatives, pour lesquelles les variables ont été observées. Cela vient du fait que la distribution la plus simple pour des données discrètes est la distribution de Bernoulli, et que le maximum de vraisemblance pour une Bernoulli est la moyenne du nombre de fois que l'événement a été observé. Cette méthode est appelée Maximum de vraisemblance (MLE).

Nous obtenons les tables de probabilités conditionnelles suivantes :

L'inconvénient de l'approche du Maximum de vraisemblance est que l'estimation du paramètre (dans ce cas-ci, la moyenne), n’indique pas la confiance dans ce paramètre. Si l'événement n’est jamais observé la valeur sera 0.
Estimation Bayésienne (Bayesian Estimation)
On peut obtenir une estimation plus précise, avec des estimateurs Bayésiens, qui prennent en compte l'espace des structures et les paramètres possibles pour trouver la structure du graphe qui reflète le plus des données. Des fonctions de score, tel que le BDeu, utilisent différents a priori (structures et paramètres) et permettent d’avoir une estimation plus réaliste.

CDP obtenues par MLE (gauche) et par Estimateur Bayésien (droite)

On peut constater que la probabilité qu’une personne ait des talents de conduite niveau expert (variable Driving skill = Expert), n’a pas une probabilité de 100% d’avoir une qualité de conduite normale (Driving Quality = Normal), mais de plutôt 60 %. En effet, cela semble être plus réaliste.
4. Les choses à garder
Les modèles Bayésiens peuvent être utiles pour :
Obtenir une vision globale et compacte des relations de dépendance entre les variables avec la structure du réseau. Cela peut être fait à partir des connaissances sur les données ou directement à partir des données seules.
Valider notre compréhension sur les relations d’indépendance entre les variables. Une fois la structure apprise, les dépendances peuvent être validées et ajoutées à une approche d’apprentissage par contraintes.
Effectuer une requête sur le graphique obtenu pour obtenir la distribution des probabilités conditionnelles pour une variable.
5. Exemple d’autres applications :
Simplification de formulaires clients en assurances vie ou assurance santé, ou tout autre domaine comptant la notion de risque. Les formulaires peuvent être optimisés en comprenant l’influence de certaines réponses, et en proposant des questions ciblées seulement quand elles sont associées à un certain risque. Les simplifications peuvent ainsi être appuyées par des modèles probabilistes et par une compréhension de structure des données.

Cela est une approche différente de l’analyse factorielle ou le but est habituellement de regrouper et d’identifier des facteurs latents, comparativement aux réseaux Bayésiens qui peuvent fournir une structure des variables existantes. L'autre différence est que les réseaux Bayésiens peuvent aussi fournir une estimation des distributions de ses variables pour justifier des décisions de simplification par exemple.
Déduire des informations d’une personne par rapport à des profils partiellement complétés.

Références
[1] Image https://bookdown.org/MathiasHarrer/Doing_Meta_Analysis_in_R/_figs/networks.jpg
{kind=link}
[2] Insurance evaluation network (synthetic) data set. https://www.bnlearn.com/documentation/man/insurance.html
[3] image librairie R : bnlearn https://www.bnlearn.com/bnrepository/discrete-medium.html#insurance
[4] Probabilistic Graphical Models: Principles and Techniques / Daphne Koller and Nir Friedman. https://list01.bio.ens.psl.eu/wws/d_read/machine_learning/BayesianNetworks/koller.pdf
[5] (2011) Bayesian Network. In: Sammut C., Webb G.I. (eds) Encyclopedia of Machine Learning. Springer, Boston, MA. https://doi.org/10.1007/978-0-387-30164-8_65
[6] Robinson R.W. (1977) Counting unlabeled acyclic digraphs. In: Little C.H.C. (eds) Combinatorial Mathematics V. Lecture Notes in Mathematics, vol 622. Springer, Berlin, Heidelberg. https://doi.org/10.1007/BFb0069178
[7] Richard E. Neapolitan. Learning Bayesian Networks. Publisher: Prentice Hall, Year: 2003
Notebook d’exemples avec la bibliothèque PGMpy : https://github.com/pgmpy/pgmpy_notebook/blob/master/notebooks/9.%20Learning%20Bayesian%20Networks%20from%20Data.ipynb